 |
Una mica de tot i a vegades més |
|


Contacte: Àlex
| SSD DIMMs |
Tot és qüestió d'ampla de banda, des de l'ADSL a qualsevol tipus de comunicació, entre elles les connexions dels discs. El SATA3 que semblava que donaria per molt amb els seus 6Gb/s ara resulta que amb els SSD no dóna l'abast. Per això hi ha SSDs que enlloc de ser SATA ja són una altra cosa, PCI-Express i similars. Ara arriba el moment d'apropar al màxim les dades al processador. I quin lloc millor que posar un bus DDR3 o similar... I posar els SSDs en els DIMMs? Fantàstics! Dit i fet!  Sandisk ha tret (de moment pel mercat empresarial) uns DIMMS fets amb memòria flash (nom de marketing ULLtraDIMM) i que tenen condensadors prou grans que quan s'envà la corrent tenen suficient càrrega per gravar les últimes dades dels buffers a la memòria flash. Suposo que serà una tecnologia encara força cara però apunta per on aniran els trets. |
| #24/01/2014 14:44 Hardware Autor: Alex Canalda |
| Desenvolupament web, part client |
Dins del desenvolupament d'aplicacions web, ja hem tractat la part de BBDD, la part servidora amb els ASHX i la clsDades. Ara cal començar amb la part client. Sempre m'ha molestat la barreja que es fa en la part client entre les diferents parts d'una pàgina web. Tal com ho he muntat he aconseguit separar la presentació (HTML+CSS), els events (jQuery i Javascript) i les dades (Ajax pel transport i JSON). 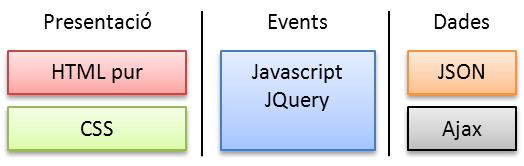 Amb aquesta separació m'he simplificat la vida i millorat la eficiència (per la xarxa no viatja HTML amb dades empotrades, només JSON), el HTML només viatja el primer cop que es carrega. Si cal canviar colors, tocar HTML o CSS, que cal modificar el comportament, tocar Javascript, que cal tocar dades, aleshores ja depen, però normalment JSON, ASHX i llestos. Pel que fa a components de .NET, per mi estan morts. Són una castanya, suposo que amb el temps han millorat però recordo que eren difícils de fer servir... Així que faig servir uns altres:
Al fer servir aquests components també té una altra avantatja. És que si algun dia la part servidora deixa de ser .NET i és PHP o qualsevol altra tecnologia, mentre es respecti l'estructura del JSON, almenys la part client seguirà funcionant. Un petit formulari quedaria com la següent imatge: 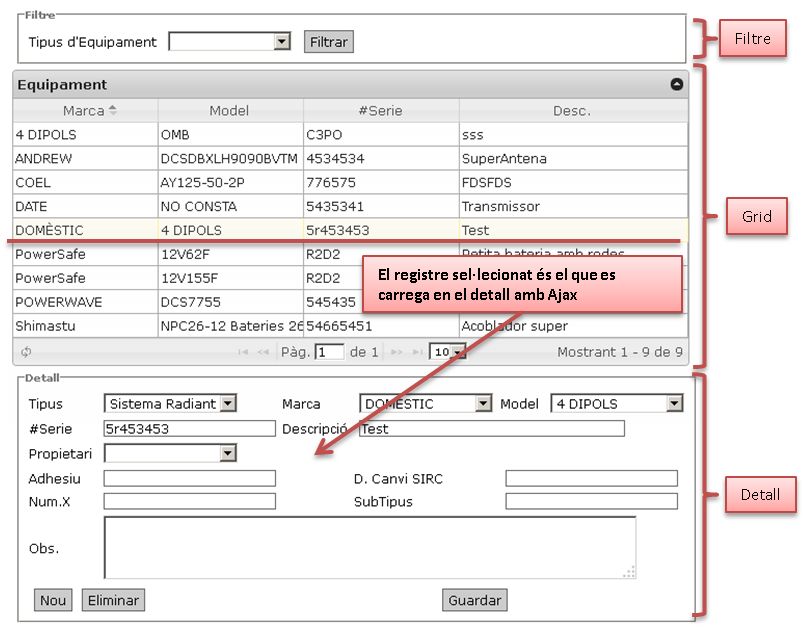 Aquest és un formulari tipus, poden variar moltes coses, per exemple que el detall sigui molt gran i necessiti una pantalla apart, que el filtre enlloc d'un camp tingui 19, que el grid el vulguin molt gran, que hagin combos depenents, grids depenents un de l'altra, etc... Tot es pot fer. També té una avantatja que és que no necessita mantenir el ViewState de .NET, estalviant molt tràfic de dades, només viatja el JSON de les poques dades del formulari, el JSON del grid, etc... Així que ara el que cal es veure les parts que he comentat en els seus corresponents posts. |
| #23/01/2014 18:24 Programació Javascript HTML/CSS Autor: Alex Canalda |
| Diferència entre Index Clustered i Non-Clustered |
Sempre que escric un Per entendre-ho cal veure que és un index: els indexos són objectes de la BBDD que ajuden en la cerca de dades dins de la BBDD. Conforme les taules es van fent grans, els indexos es fan indispensables per fer-hi cerques. Tenen una estructura en forma d'arbre, on hi ha una arrel i moltes fulles que són el nivell final. Quan es fa una cerca es mira la clau de l'index per tal fer el menor nombre de lectures possibles fins a arribar a les fulles.  De moment hem vist el que és un índex, ara cal veure la diferència, que està en el format de les fulles. En un index de tipus clustered, les dades de la taula es troben a la mateixa fulla, per tan un cop arriba la lectura de la fulla ja es tenen les dades disponibles.  En canvi en un index Non-Clustered el que hi ha a les fulles és un punter a les dades, cal fer un "bookmark lookup" (una lectura extra) per arribar fins les dades.  Òbviament els index Non-clustered tenen un rendiment inferior a un Clustered donat que tenen que fer una lectura més. Des de SQL Server 2005, es permet posar dins d'un index Non-Clustered camps que no formen part de la clau de l'index per tal d'evitar fer aquesta lectura extra i millorar el rendiment. Respecte com s'inclouen camps a un index, les limitacions sobre incloure camps, ... hi ha un article de la Technet que ho explica, amb exemples. Tampoc es poden definir tots els indexos com Clustered, ja que només es permet un únic index d'aquest tipus en una taula. La raó és que en realitat els registres estan guardats a disc juntament amb l'index, ordenats seguint l'index i clar, no es pot tenir dos ordres físics alhora. Punts a tenir en compte al fer servir indexos:
|
| #22/01/2014 15:33 Programació SQLServer Autor: Alex Canalda |
| Desenvolupament web, part servidora: comboloader |
Potser m'avanço a coses que explicaré en la part client, però en una aplicació web, si es vol separar la presentació de les dades hi ha un punt de conflicte que són els combos (desplegables). Les pàgines que genero només tenen HTML, sense dades, cal doncs un mecanisme per omplir els combos. De moment començaré per explicar la part servidora, un ASHX que es diu comboloader. Aquest ASHX, s'encarrega de gestionar tots els combos de l'aplicació. Es recolza en la clsDades i derivades on normalment fa servir el mètode GET per anar obtenir els registres, muntar-los en JSON i enviar-los al navegador (al client). La part Javascript del comboloader s'encarrega de desmuntar aquest JSON i posar els valors corresponents als combos. Llavors quan es dissenya una pàgina un combo només és tag <select>, sense valors dins (a vegades es poden posar els valors si són coneguts i no hi ha gaires (ni previsió que hagin més)). Del navegador es reben un conjunt de combos a carregar (els seus noms venen separats per "-"), els que apareixen en una pàgina i el que es fa es generar-los tots de cop. Per fer això necessitarem objectes que, un cop convertits a JSON donin suport a l'enviament de tots els combos amb els seus valors de cop. Són les classes: Combo i ComboItem. Són dues classes molt senzilles. Comentar que potser hi ha combos en diferents parts de l'aplicació que tenen els mateixos items però diferents noms, aleshores el que es fa és afegir al "switch" que escull el combo a muntar més opcions. Això fa que moltes vegades ens trobem que el combo que volem muntar en realitat ja està fet per una altra pantalla. Llavors amb una simple línia de codi ja ho tenim enllestit. La construcció dels combos segueix la següent descripció: 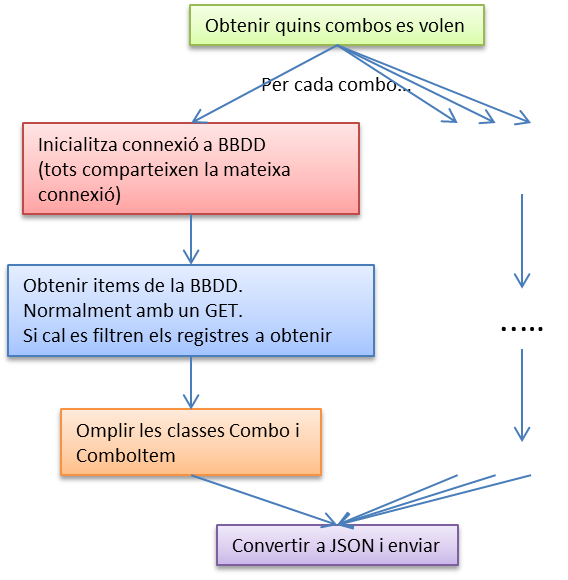 Com sempre el codi de cada fase, comencem per "obtenir els combos" i també al final "convertir a JSON i enviar": Ara toca la funció que inicialitza totes les connexions de les classes derivades. Ara toca el pas d'obtenir els valors: L'únic que falta és muntar els ítems dels combos. |
| #21/01/2014 22:54 Programació C# Autor: Alex Canalda |
| La fiabilitat dels discs durs |
Qui més qui menys ha patit la pèrdua de dades deguda a que un disc dur ha mort. El nivell de la destrossa ja depèn del backup que un faci. Doncs una empresa de copies de seguretat, Backblaze, ha publicat un estudi sobre 25.000 discos, amb marques i models, on mostra les estadístiques d'errors dels discs. Veient les gràfiques Seagate no queda gaire ben parada.   Els propers discs els agafaré Hitachi. De moment faig servir Western Digital. |
| #21/01/2014 22:09 Hardware Autor: Alex Canalda |
| Desenvolupament web: clsJSON |
En tota aplicació web, la part servidora té números que hagi d'enviar dades en format JSON. El mètode que he triat jo és fer servir una llibreria lliure que converteix objectes a JSON, i per la quantitat de projectes que porto amb aquesta llibreria funcionant bé, crec que ja és hora de recomanar-la. És la NewtonSoftJSON. La particularitat que té i que m'agrada és que el valors NULL no els converteix a JSON, fent que sigui força optim enviar dades en JSON. Altres llibreries els valors NULLs es serialitzen com a: "nom_de_la_propietat":"", en aquesta és configurable. En el codi aquesta llibreria acostuma a aparèixer com un clsJSON.Serialize(objecte_dictionary) en els ASHX. Al ser una llibreria no posaré el codi per que seria només la línia que he comentat abans, però si cal recordar que s'ha de posar una referència a la DLL corresponent.  |
| #20/01/2014 11:24 Programació C# Autor: Alex Canalda |
| Por la cara (Identity Thief) |
Diumenge de pluja, peli absurda al canto. Comèdia que intenta fer riure però que no es creu res del que passa ni el tato. Tracta d'un empleat exemplar i poc valorat al que una dóna li roba les dades i comença a gastar els seus diners. Llavors decideix anar-la a buscar, la troba i la porta cap al seu estat (als USA són gairebé com països diferents). En el viatge de tornada, es cauen molt bé i la delinqüent que té un cor daurat decideix anar a la presó i arreglar els estropicis que ha fet. No recomano veure-re-la a menys que diguis: "pse, està plovent, posem algo a la TV i no hi fem gaire cas". Eliminada!  |
| #20/01/2014 11:10 Pelis Autor: Alex Canalda |
| Desenvolupament web, part servidora: LoadGrid - part clsHelper |
Dins de la construcció d'un grid, en la part que toca a un ASHX, el que cal saber és la seva configuració i com funcionen la clsColumna i clsCampBBDD. No cal conèixer en detall aquesta funció de la clsHelper, però si ens agrada el codi com a mi, no està de més saber com funciona per dins. Tots el grids d'una aplicació fan servir aquesta funció, porto uns quants projectes a l'esquena fent-la servir, així que penso que està amortitzada i no he trobat bugs aparents, però si en trobo almenys al corregir-ho serveix per tots. El primer que fa aquesta funció és recuperar els valors dels paràmetres que indiquen la pàgina, l'ordre, etc... aquest paràmetres els genera el grid automàticament a la part client, en la part servidora només els recuperem.
Durant el procés de recuperar aquests valors també es munta una clau que identifica de forma única un grid, i l'estat en que es troba. Com estat en que es troba s'enten: la pàgina, ordre, número de registres, filtre aplicat etc... Aquesta clau es fa servir per consultar la cache. A la cache de grids s'accedeix mitjaçant aquesta clau, un identificador de grid i la taula sobre la que s'aplica. Les operacions d'INS, UPD i DEL, en cas de tenir cache que la taula es gestioni amb cache, esborren els registres de la taula de cache només d'aquesta taula en concret. Un muntada aquesta clau es mira la taula de cache, si es troba es recupera el JSON i s'envia directament. D'això s'anomena un "cache hit". Si no es troba (un "cache miss") es segueix processant normalment i es crida a la funció QUERY (aquesta al seu temps cridarà a la SP QUERY). La diferència entre operar amb cache o sense és molt gran quan es fan QUERYs contra taules de milions de registres ja que els usuaris acostumen a treballar habitualment amb el mateix subconjunt de dades, es a dir no tots els registres tenen la mateixa importància. Un cop obtinguts els registres cal empaquetar els camps en els objectes clsGridRow corresponents, donant format a les dades en cas de que estigui informat el camp "Format". Un cop fet això poc queda per fer. Convertir-ho a JSON. Si la taula es gestiona amb cache, aquest JSON cal guardar-lo, d'aquesta manera el proper cop hi haurà un "cache hit" (de fet només que l'usuari refresqui la pàgina ja farà un hit). Com sempre el codi: |
| #17/01/2014 13:47 Programació C# Autor: Alex Canalda |
| Desenvolupament web, part servidora: LoadGrid - part ASHX |
Quan en una aplicació web, en un ASHX, es fa un grid hi ha que fer una crida a la clsHelper LoadGrid amb uns paràmetres en concret. Aquests paràmetres es creen fent servir les classes clsColumna i clsCampBBDD que estàn explicades aquí. Cal tenir en compte que alhora de definir les columnes aquestes han d'estar en el mateix ordre que al grid. En el codi a continuació es poden veure exemples de columnes compostes per més d'un camp de BBDD, formatades, que passa si el valor és null, etc... Millor veiem l'exemple: |
| #17/01/2014 13:06 Programació C# Autor: Alex Canalda |
| Desenvolupament web, part servidora: LoadGrid |
Els grids són la part més difícil d'una aplicació web. Jo faig servir el papa de tots els grids: el Trirand jqGrid. De fet ja fa força anys que el faig servir (uis! hem faig vell!). Com aquí em tinc que limitar a tractar la part servidora que està en un ASHX, direm que l'objectiu és: donada una petició cal muntar el JSON corresponent per alimentar al grid. Muntar aquest JSON té certa gràcia ja que ha de tenir una estructura concreta, per això cal fer unes classes que quan es converteixen a JSON encaixin amb el que necessita el grid. A més a més d'això cal cridar a mètode QUERY de la classe derivada de la clsDades corresponent. Per ja fer triple carambola, hi ha columnes d'un grid que estan compostes de varis camps de la BBDD ajuntats. Començarem doncs per les classes que s'han d'omplir per generar el JSON, són la clsGridResponse i la clsGridRow: Per descarregar una mica la complexitat de definir un grid amb columnes compostes de varis camps de la BBDD, vaig fer uns altres objectes on informar aquesta configuració, són les clsColumna i la clsCampBBDD. I aquestes classes de suport on es poden posar? Doncs tota aplicació té un calaix de mals endreços on van a parar aquest tipus d'objectes. En el meu cas es diu clsHelper, i mereix un post apart. Aleshores, per fer un grid, el que cal fer es configurar aquestes classes i cridar al Loadgrid genèric de la clsHelper, un exemple d'aquesta configuració. |
| #16/01/2014 17:43 Programació C# Autor: Alex Canalda |
| << Posts anteriors | Posts més recents >> |